
たくさんの機能があるpandasですが、Excel初級者程度のデータ操作ができるようになることを目指して厳選した内容です。コードをColaboratoryにコピペすればそのまま実行できます。
pandasとは
NumPyとpandasは、ともにExcelのような多次元配列計算を行うライブラリですが、NumPyは数値に特化して計算速度が速いのに対し、pandasは文字列や時系列データを扱うことができ、統計処理も得意です。Pythonによる機械学習の流れの中では、pandasでデータの前処理を行い、NumPyのndarrayデータに変換してから解析に使われることが多いのです。
pandasのインポート
import pandas as pd
pandasのUser Guide冒頭では、NumPyもインポートするよう書かれていますが、本稿ではあくまでもpandasでできることに特化して説明しています。
ファイルの読み書き
以下の例のデータはColaboratoryに元々置いてあったsample_dataフォルダ内のものを使っています。自分のデータを使うときはファイルツールでアップロードしてください。
df = pd.read_csv('sample_data/california_housing_train.csv') # CSVの読み込み
df.to_csv('california_housing_copy.csv') # CSVに書き出し
df.to_excel('california_housing_copy.xlsx', sheet_name='pandas') # Excelに書き出し
df1 = pd.read_excel('california_housing_copy.xlsx', sheet_name='pandas') # Excelの読み込み
ファイルの読み書きでは特に出力はありません。エラーが出なければOKです。
pandasはpdという名前でimportするのが慣習だよ。ファイルを読み込む変数名のdfは、pandasのデータ形式であるDataFrameの頭文字から来ているんだ。Excel書き出し時にシート名を省略するとSheet1になり、Excel読み込み時にシート名を省略すると最初のシートが読まれるんだ。
なお、サンプルデータの説明は以下のコマンドで確認できます。
!cat sample_data/README.md
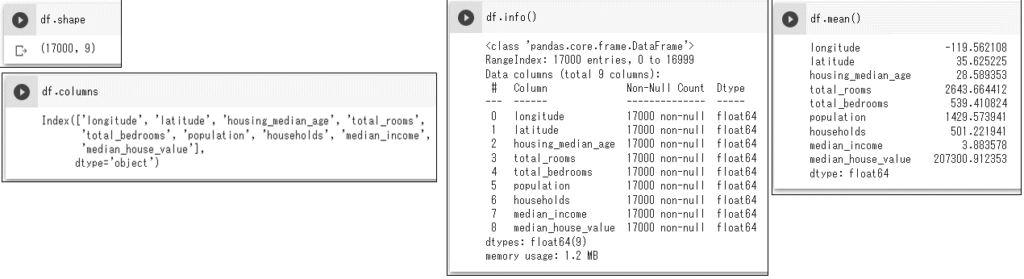
データの確認
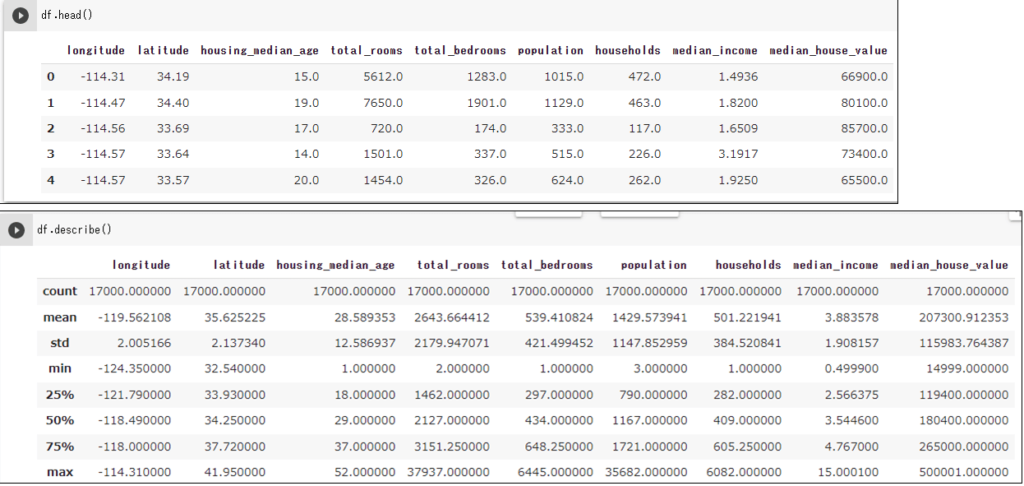
df.shape # 配列サイズ確認 df.columns # カラム名確認 df.info() # カラム名・データ型や配列サイズ確認 df.head() # 先頭5行確認。整数を指定するとその行数を確認。 df.tail() # 末尾5行確認。整数を指定するとその行数を確認。 df.describe() # 列ごとのデータ数、平均、標準偏差、最大、最小など df.mean() # 列ごとの平均。median, sum, count, std, min, maxなども可能 df.mean(1) # 行ごとの平均。median, sum, count, std, min, maxなども可能
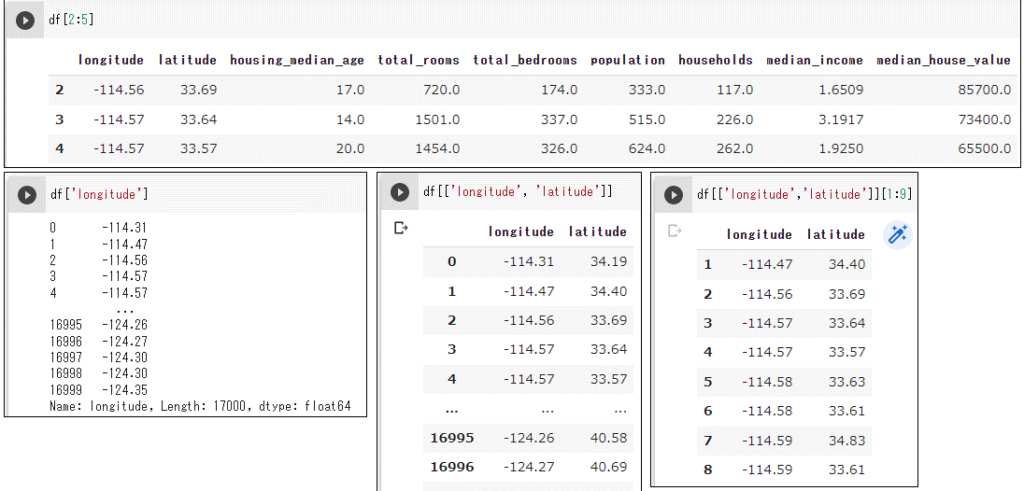
行・列の一部を取り出し
以下の操作はdfを変更せず、新たなDataFrameを返します。dfに代入すると、dfを書き換えることができます。
df['longitude'] # 1列取り出し df[['longitude', 'latitude']] # 複数列取り出し df[2:5] # 2~4行取り出し df[['longitude','latitude']][1:9] # 2カラム×1~8行取り出し df[df['median_income'] > 10.0] # 条件に合致する行取り出し
行・列の一部を削除
以下の操作はdfを変更せず、新たなDataFrameを返します。実際に削除するには、dfに代入する必要があります。
df.drop(['housing_median_age', 'total_rooms'], axis = 1) # 列を削除 axis = 1は列 df.drop([0,1,3]) # 行を削除 axis = 0は省略可 df[::10] # 10行間隔で間引く
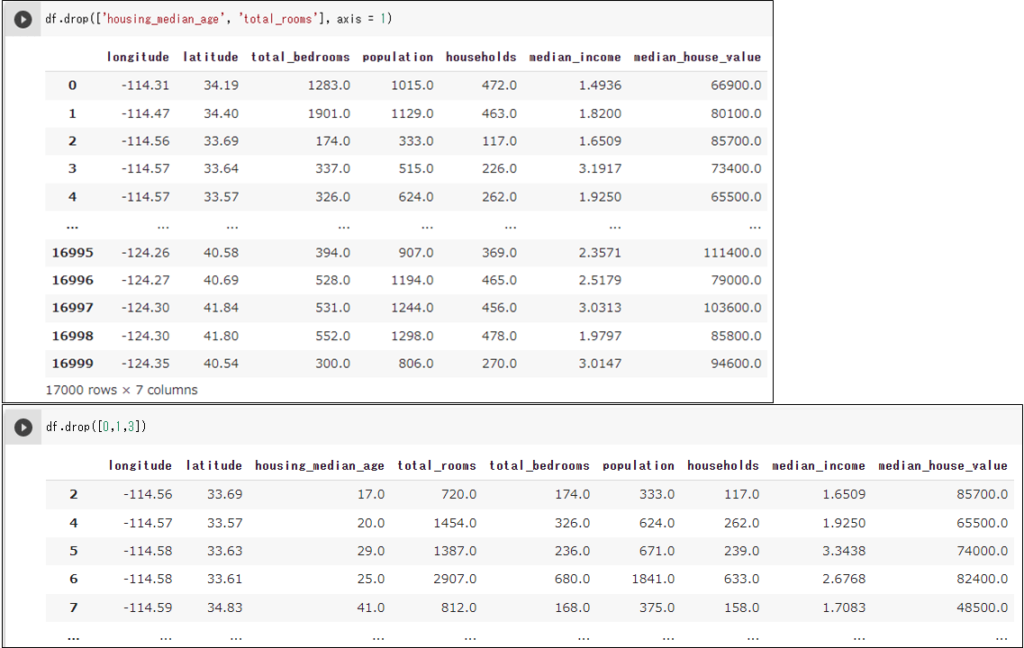
「行・列の一部を取り出し」たものをdfに代入することで、実質的にdfの取り出されなかった部分を削除することもできます。
並べ替え
以下の操作はdfを変更せず、新たなDataFrameを返します。df自体を並べ替えるには、dfに代入する必要があります。
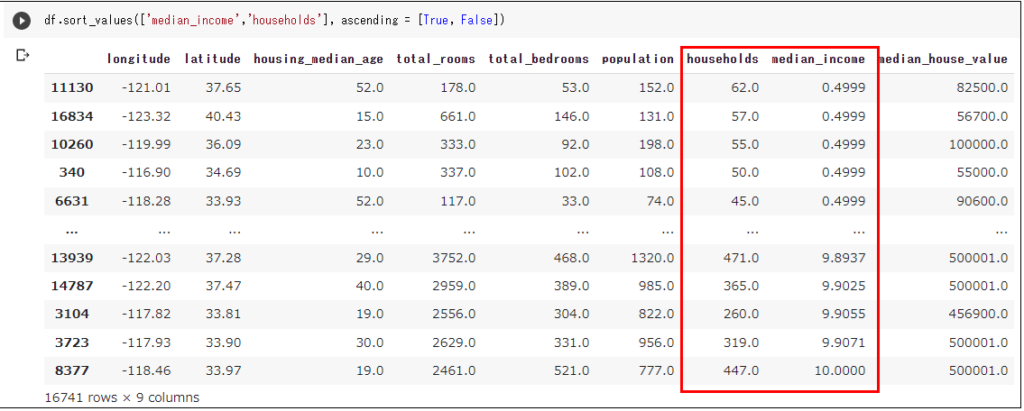
df.sort_values('median_income') # 行を並べ替え
df.sort_values('median_income', ascending = False) # 行を逆順で並べ替え
df.sort_values(['median_income','households'], ascending = [True, False]) # 複数指標で並べ替え
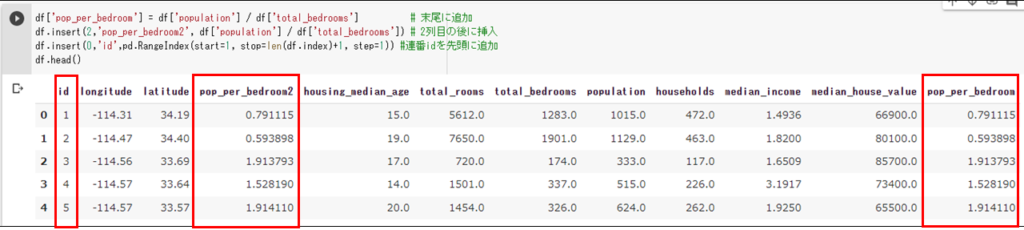
計算して新たな列に代入
以下の操作は、dfを変更します。
df['pop_per_bedroom'] = df['population'] / df['total_bedrooms'] # 末尾に追加 df.insert(2,'pop_per_bedroom2', df['population'] / df['total_bedrooms']) # 2列目の後に挿入 df.insert(0,'id',pd.RangeIndex(start=1, stop=len(df.index)+1, step=1)) #連番idを先頭に追加
三角関数や指数・対数を計算するにはNumPyライブラリもインポートする必要があります。
import numpy as np df['log_median_house_value'] = np.log(df['median_house_value'])
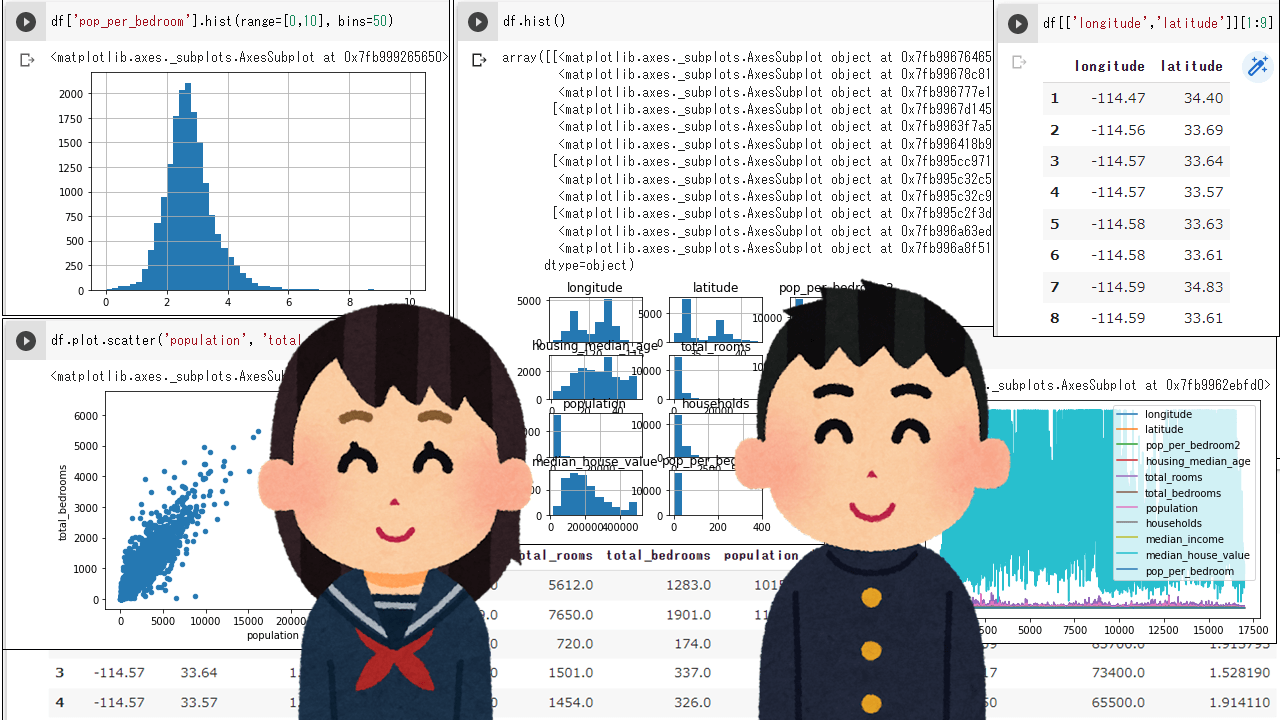
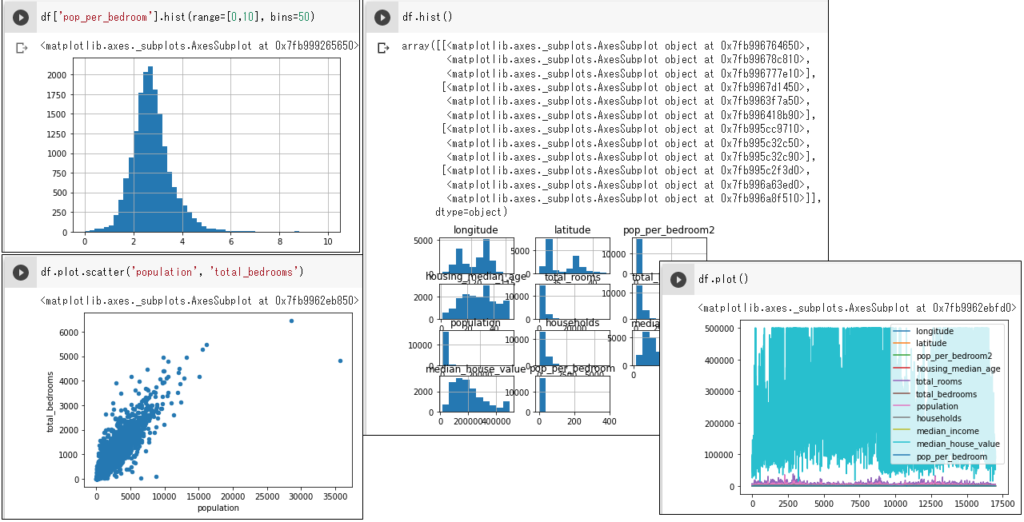
グラフ
グラフ作成は、pandas内部でmatplotlibを呼び出しています。
df['pop_per_bedroom'].hist(range=[0,10], bins=50)# histgram. range:階級範囲、bins:階級数
df.hist() # 全変数のhistgram
df.plot.scatter('population', 'total_bedrooms') # 散布図
df.plot() # 全変数の折れ線グラフ
pandasのDataFrameをNumPyのndarrayに変換する
nd = df.values # DataFrameをndarrayに変換

pandasはたくさんの機能があるけど、全部覚えるのは大変かも。基本機能を組み合わせればたいがいの目的を達成できるわ。頭をやわらかくして工夫してね。
もっと勉強したい人は公式マニュアルを見てね。 Have fun!
コメント